Digitalisaatio
Julkaistu : 28.11.2024
Generatiiviset tekoälysovellukset tarvitsevat dataa oppiakseen. Chat GPT 4.0:n taustalla on esimerkiksi lokakuuhun 2023 mennessä julkaistua dataa. Chat GPT:n kouluttamiseen käytetään myös GPTBot-nimistä indeksoijaa, ja kuka tahansa nettisivuston ylläpitäjä voi antaa indeksoijalle pääsyn ja käyttöoikeuden sivustolla julkaistuun aineistoon. Googlen Gemini-tekoäly käyttää omaa indeksoijaa nimeltään Google Extended. Indeksoijien pääsyn omalle sivustolle voi myös kieltää, ja näin esimerkiksi Amazon ja The New York Times ovat tehneet Chat GPT:n kohdalla.
Indeksoijien ja luovan työn tekijänoikeuksien suhdetta on pitkään pidetty ongelmallisena, sillä indeksoijat skannaavat nettisivuja ja tallentavat hakukirjastoon tietoa nettisivuilta tekijänoikeuksista välittämättä. Jos käytät oppilaitoksen ulkopuolisia palveluita ja sovelluksia ja julkaiset materiaalia kaikille avoimen linkin kautta, et voi tietää, onko tekoälylle syötettä tuottavalla indeksoijalla pääsy sovelluksen sisältöön vai ei. Mikäli indeksoija on sallittu, julkaisemasi aineisto saattaa päätyä tekoälysovelluksen koulutusmateriaaliksi. Kielimallit eivät tekijänoikeuksia ymmärrä, joten tekijänoikeuksien noudattaminen perustuu siihen, miten hyvin ne otetaan huomioon koulutusdatassa ja verkkoindeksoijien toiminnassa.
Noudattavatko verkkoindeksoijat tekijänoikeuslakeja?
Kielimallien kouluttaminen ei ole välttämättä huono asia. Ongelmallista on se, jos aineisto loukkaa tietosuojaa tai on tekijänoikeuden alaista. Verkkoindeksoijat, kuten ChatGPT-3:n kehittämiseen käytetty CCBot, vierailevat verkkosivustoilla, skannaavat niillä avoimesti julkaistua tietoa ja tallentavat tätä tietoa säännöllisesti omiin tietokantoihinsa, joita käytetään koneoppimisen prosessissa. Juuri tämä tietojen kopiointi on asia, jonka nähdään rikkovan tekijänoikeuksia, sillä sen katsotaan olevan paitsi pysyväisluoteista, myös kaupalliseen ja ammattimaiseen käyttöön tarkoitettua (Kamocki & Popescu 2018).
Euroopan unionin alueella julkaistujen teosten yleiseen käyttöön ei ole samankaltaista ”fair use”-periaatetta kuin Yhdysvalloissa, vaan kunkin maan omaa tekijänoikeuslainsäädäntöä on noudatettava. Euroopan unionin tekijänoikeusdirektiivin myötä Suomen tekijänoikeuslainsäädäntöön lisättiin pykälä 13b, joka sallii kopioiden tekemisen koneoppimisen ja tiedonlouhinnan tarkoitukseen. Useat tahot ovat kuitenkin todenneet, ettei laissa mainita tekoälyä tai kielimalleja, ja siten pykälän soveltaminen verkkoindeksoijien toimintaan ja kielimallien algoritmien kouluttamiseen käytettävään aineistoon on hyvin epäselvää (Neuvonen 2024; Honkasalo 2023).
Tekijänoikeuslain 13b § ei edellytä sivuston ylläpitäjän antamaa lupaa tiedonlouhinnalle ja datan kopioinnille – sen sijaan sivuston ylläpitäjän pitää erikseen estää tiedonlouhinta. Jos verkkosivusto haluaa jättäytyä tiedonlouhinnan ulkopuolelle ja estää sivustolla julkaistun aineiston kopioinnin ja käytön koneoppimiseen, verkkoindeksoijien toiminnan tulisi olla yksityistä, satunnaista ja ei-kaupallista, tai ne eivät voi hakea kyseiseltä sivustolta tietoa lainkaan. Verkkosivustoilla on toki kannustumia hyväksyä verkkoindeksoijien datankeruu vähintään hakukoneiden takia, koska se vaikuttaa sivustojen löydettävyyteen ja vierailumääriin. Sivuston ylläpitäjät tekevät siis sekä eettistä että laillisuuteen perustuvaa harkintaa päättäessään, antavatko verkkoindeksoijille oikeudet vai käyttävätkö esimerkiksi Chat GPT:n tarjoamaa ”opt out”-mahdollisuutta.
Tasapainoilua avoimen jakamisen ja tekijänoikeuksien välillä
Chat GPT-3:n kouluttamiseen käytettiin CCBotia, ja sen tarkoitus on koota ja tarjota tieto maksutta kaikille kielimallin kuratoimana ja muokkaamana. Samalla tavalla erityisesti tutkimus- ja opetusalalla kannustetaan avoimeen julkaisemiseen ja jopa oman oppimateriaalin avoimeen jakamiseen Creative Commons-lisensseillä. Creative Commons-lisenssit tuntevalle CCbotin nimi saattaa vaikuttaa tutulta, ja nimeäminen tuskin on täysin sattumaa. Tiedon avoimuuden ajatukseen liittyy myös pulmia, kun tiedon käyttäjänä on ihmisen sijaan sovellus.
CC-lisensoituja avoimesti julkaistuja aineistoja voi sekä tekijänoikeuslain että itse lisenssiehtojen mukaan yleensä käyttää tiedonlouhintaan eli myös tekoälysovellusten koneoppimisen (Asianajotoimisto Lindblad & Co 2024). Periaate on siis se, että kaikkea CC-lisensoitua aineistoa saa kuka tahansa käyttää, ja myös muunnelmia ja kopioita saa tehdä, jos alkuperäisen tekijän mainitsee ja jakaa samalla lisenssillä (CC-BY-SA). Creative Commons-lisenssejä on kuitenkin monenlaisia, myös sellaisia, joissa aineiston muuntelu (CC-BY-ND) ja/tai kaupallinen käyttö (CC-BY-NC) on kielletty. Vain CC0-lisenssi on sellainen, jossa aineisto on tarkoitettu vapaaseen käyttöön, kopioita ja muunnelmia saa tehdä eikä tekijää tarvitse mainita.
Kielimallien ja varsinkin niiden maksullisten versioiden käyttö on kuitenkin kaupallista toimintaa, ja jos kielimallin koneopettamisessa on käytetty kaupallisen käytön kieltävää CC-lisensoitua aineistoa, voidaan ajatella, että lisenssin tarkoitusta ja oikeuksia on silloin loukattu. Samoin kielimallin käyttäjä voi hyödyntää esimerkiksi Chat GPT:n tuotosta kaupallisessa toiminnassa, jolloin hän saattaa tulla rikkoneeksi lisenssiehtoja. Lisäksi tekoälysovellusten voi katsoa nimenomaan muuntelevan aineistoa ja käyttävän niitä tekijän nimeä mainitsematta. Kielimalli ei tuotostaan tarjoillessaan yleensä mainitse alkuperäistä tekijää eikä kunnioita tekijän taloudellisia oikeuksia. Indeksoijat eivät tunnista CC-lisenssejä eivätkä osaa jättää tiukimmalla CC-lisenssillä varustettuja aineistoja tekoälyn koulutusmateriaalin ulkopuolelle. Esimerkiksi opettajan CC-BY-SA-ND-lisenssillä avoimeksi julkaisema aineisto – jossa lisenssi siis edellyttää tekijän mainitsemista ja kieltää muunnelmien tekemisen – saattaakin olla koulutusmateriaalia tekoälylle, joka käyttää sitä surutta tuotoksensa taustalla.
Copilot lienee tällä hetkellä laajoista kielimalleista ainoa, joka antaa edes jonkinlaisia viitetietoja lähteisiin, josta se hakee ja yhdistelee tarjoilemansa tiedon. Chat GPT tarjoaa lähteitä vain maksullisessa versiossa, vaikka oletettavaa on, että sekä ilmaisen että kaupallisen version taustalla on sama koneoppimisen prosessi. Ottaako ilmaisversion käyttäjä siis tietämättään jonkinlaisen riskin tekijänoikeuksien suhteen käyttäessään kielimallin tuottamaa aineistoa?
Microsoft tarjoaa organisaatioille mahdollisuutta sisällyttää organisaation oma sisäinen data Copilotin syötteeksi. Jos Copilotille sallii pääsyn kaikkeen oppilaitoksen Sharepointissa, Teamsissa, Power BI:ssa ja muissa sovelluksissa olevaan dataan, kaikki avoimien linkkien kautta jaettu aineisto on käytännössä CC0-tasolla. Opettaja voi siis epähuomiossa antaa opetusmateriaalinsa tai opiskelijoiden työstämän materiaalin organisaatiokohtaisia tietokantoja hyödyntävän kielimallin syötteeksi jakaessaan sen organisaatiotasolla avoimen linkin kautta nähtäville tai muokattavaksi. Silloin kollega voi saada Copilotilta vastauksen, joka käyttää toisen työntekijän jakamaa opetusmateriaalia vastauksen lähteenä. Asiassa ei liene tekijänoikeusongelmaa sikäli, jos organisaatio omistaa sopimusten perusteella henkilökunnan työssään tuottaminen materiaalien kaikki tekijänoikeudet. Silloin organisaatio saa päättää, kuka käyttää esimerkiksi opettajien laatimaa oppimateriaalia ja miten.
Tekijänoikeusrikkomuksia vakavampi ongelma syntyy silloin siitä, jos tällaisessa vahingossa syötteeseen päätyvässä aineistossa on opiskelijoiden henkilötietoja. Kielimallin takana toimivan datan indeksoija pitäisi osata jättää yksilöivät henkilötiedot algoritmin toiminnan ulkopuolelle, tai ainakin sen pitäisi osata anonymisoida data jo keräysvaiheessa (Kamocki & Popescu 2018). Koska kielimallien takana oleva datankeruuprosessi ja algoritmin toimintaperiaatteet eivät ole julkista tietoa, on mahdotonta sanoa, toteutuuko henkilötietojen suojaaminen oikein.
Kuka rikkoo kenenkin tekijänoikeuksia?
Kun esimerkiksi opettaja perehtyy johonkin uuteen asiaan ja vaikkapa valmistelee opetusmateriaalia muiden julkaisemien CC-lisensoitujen aineistojen pohjalta, hän eettisesti toimiessaan viittaa asianmukaisesti alkuperäiseen tekijään. Immateriaalioikeudella suojattujen aineistojen kohdalla lähteenä käytettyjen teosten tekijän mainitsematta jättäminen on plagiointia, ja kukaan opettaja tuskin harkitsee oman opetusaineistonsa julkaisemista avoimeksi, jos tekijänoikeuksia on rikottu harkitusti.
Kun kielimalleja pyydetään tuottamaan aineistoa, tuotoksen tekijänoikeuden määrittelystä tulee hyvin ongelmallista. Lyhyen yleisellä tasolla olevan promptin avulla tehtyyn tuotokseen ei tekoälysovelluksen käyttäjällä synny tekijänoikeutta, mutta kun tuotosta työstää kielimallin kanssa enemmän, tilanne voi olla toinen (Venkula 2024). Tekoälyllä tehdyn tuotoksen tekijänoikeuksien lisäksi pitäisi pohtia myös alkuperäisen koneoppimiseen käytetyn aineiston tekijänoikeuksia ja sitä, onko koneoppimisessa kunnioitettu tekijänoikeuksia. Kenen ja millä lisenssillä julkaistuun aineistoon kielimallin tuotos perustuu? Mitä sillä saa tehdä ja missä sen saa julkaista? Jos tekijänoikeuksia rikotaan, kuka niitä rikkoo – tekoälysovellus, sen kehittäjät tai tekoälyn kouluttamisessa käytetty indeksoija, vai kenties sovelluksen loppukäyttäjä?
Kielimallien kehittäjät vetoavat koneoppimisen monimutkaisuuteen: dataa on niin valtavasti, että on mahdotonta väittää jonkin teoksen olevan kielimallin vastauksessa laajasti referoituna. Näin ollen kielimallien toiminta itsessään ei kehittäjien näkökulmasta riko tekijänoikeuksia, vaikka joskus sen tuotos näyttäisikin perustuvan pitkälti yhteen tiettyyn lähteeseen (OpenAI 2024). Samalla tavalla ihmisen on vaikea muistaa tai eritellä, mistä hän on joskus jonkin oppimansa asian lukenut tai kuullut. Algoritmista alkuperäisen lähteen saa kuitenkin jäljitettyä, ja OpenAI kutsuu tiedon kopioitumisen ongelmaa tai bugia tahattomaksi muistamiseksi ja toistoksi (ibid). Kielimallien tekijänoikeusongelman ydin ei kutenkaan ole koneoppimisen malleissa sinänsä vaan suurilta osin verkkoindeksoijien toiminnassa.
Nämä ongelmat eivät ole aivan uusia, sillä jo 2010-luvun taitteessa Wolfram Alpha-hakukoneen julkaisun yhteydessä keskusteltiin hakukoneiden ja tekijänoikeuksien suhteesta. Wolfram Alpha ilmoitti, että sen hakutulosten käyttäminen Wolfram Alphaa mainitsematta johtaa todennäköisesti tekijänoikeusloukkaukseen tai jopa plagiointiin (McAllister 2009). Vastineena yhdysvaltalainen vapaan ohjelmistokehityksen pioneeri Richard Stallman muotoili asian siten, että tietokoneelle ei muodostu samanlaista tekijänoikeutta kuin ihmiselle, eikä hakukoneen antamien hakutulosten käyttäminen ole siksi plagiointia (Stallman 2009). Näin ollen hakutuloksia hyödyntävä loppukäyttäjä olisi vapautunut plagiointisyytöksistä, mutta aivan näin yksioikoinen asia ei välttämättä ole nykyisen tekoälyn kanssa.
Tekoäly, keinoäly, kenen äly?
Tekijänoikeudet ovat immateriaalioikeuksia ja koskevat luovaa työtä. Englannin kielellä puhutaan termillä intellectual property rights (IPR), joka nimenomaisesti viittaa älykkään työn lopputulokseen. Kyse onkin ehkä siitä, onko tekoälysovellus älykäs ja luova ihmisen tavoin.
Nykyiset kielimallit ovat toki lähempänä ihmisenkaltaista älykkyyttä kuin perinteiset hakukoneet 2010-luvulla. Älykkyys tieteellisenä käsitteenä ei sulje pois kielimallien älykkyyden tunnustamista, eikä tutkijoiden mukaan ’…ole mitään periaatteellista syytä, miksi luova yhdistelyprosessi olisi mahdollinen vain ihmisaivoille.’ (Pesonen & Reijula 2024.) Pesonen ja Reijula muistuttavat, että inhimillisellä luovuudellakin on rajansa ja että arjen toiminta toteutuu usein pitkään kokemukseen perustuvaan automaatioon, joka ilmenee tietynlaisina intuitiivisina ratkaisuina (ibid).
Sinänsä tekoälyn koneoppimisen ja ihmisen intuitiivisen toiminnan prosessi lienee samankaltainen, joten siinä mielessä ihmisen ja tekoälyn toiminta myös luovassa työssä on verrattavissa toisiinsa. Ehkä Wolfram Alphan kehittäjien ajatus teknologian tekijänoikeudesta ei olekaan tuulesta temmattu. Samaan ajatukseen päätyi myös Neil McAllister – mutta asia jää hänen mielestään lainoppineiden ratkaistavaksi (McAllister 2009).
Voisiko siis ajatella, että kielimallillakin olisi älykkyyttä, ja sen myötä itsenäinen kyky luovaan työhön? Voiko silloin sanoa, toisin kuin Stallman väittää, että tekoälysovellus tai ainakin sen kehittäjä voisi saada tuotokseen tekijänoikeudet tai edes lähioikeuksien suojan? Olisiko itse kielimallisovellus samalla vastuussa tuotoksistaan? Pitäisikö Chat GPT:n, Geminin ja Copilotin oppia lisäämään lähdeviitteet kaikkiin tuotoksiinsa? Vai siirtyykö vastuu kielimallin käyttäjälle, kuten nyt tuntuu olevan? Ja jos tuotos syntyy olennaisesti yhteistyössä kielimallin ja käyttäjän pitkän keskustelun tuloksena, voiko tuotos olla teoskynnyksen ylittävä ja onko tekijänoikeus silloin jaettu? On syytä miettiä, kenen älyä ja hengentuotosta oikeasti käytetään tässä prosessissa.
Avoimen julkaisemisen ja tekijänoikeuksien tulevaisuusskenaarioita
Tekoälysovelluksen kehittäjä on toki vastuussa koneoppimisprosessissa käytetyn aineiston tekijänoikeuksien noudattamisesta, ja omistaa samalla algoritmin tekijänoikeudet – mutta ei toistaiseksi oikeuksia siihen, mitä kielimalli algoritmin pohjalta ja käyttäjän hakukäskyn seurauksena tuottaa. Jos tekoälysovelluksella tai kielimallilla katsottaisiin olevan tekijänoikeus lopputuotoksiin, se veisi pohjan kielimallien alkuperäisestä ajatuksesta eli tiedon avoimesta jakamisesta ja hyödyntämisestä. Laajojen kielimallisovellusten kehittäjillä voisi olla oikeus vaatia laajoja tekijänoikeuksia, ja tekoälystä tulisi vain maksavien asiakkaiden oikeus. Kärsijänä silloin on toki avoin tiede ja tutkimus, ja todennäköisinä hyötyjinä isoja voittoja tekevät teknologiayhtiöt sekä mediayhtiöt, jotka omistavat ison osan taiteen, viihteen ja urheilun tekijänoikeuksista.
Toisaalta se varmistaisi kehityssuunnan, jossa olisi pakko miettiä toimivia keinoja tekijänoikeuksien koneelliseen analysoimiseen ja tunnistamiseen sekä kielimallien kouluttamisessa käytettyjen aineistojen rajaamiseen. Käytännössä tämä tarkoittaisi esimerkiksi erilaisia uudenlaisia rajoitteita verkkoindeksoijien toimintaan, maksumuurien, captcha-kyselyjen, kryptauksen ja salasanasuojauksien lisäksi. Se tarkoittaisi myös uusia rajoituksia tekoälytyökalujen käyttäjille, mikä itsessään todennäköisesti hidastaisi tekoälyn avointa kehittämistä ja hyödyntämistä yhteiskunnassa.
Digitaalisille sovelluksille ja alustoille tuskin ollaan myöntämässä ihmiskirjailijoiden, taiteilijoiden ja tutkijoiden nauttimaa teoksen tekijän tai luojan statusta. Sen sijaan tekoälyn kehitys saattaa muuttaa jatkossa tekijänoikeuslainsäädäntöä radikaalisti. Idean saa nykylainsäädännön mukaan kopioida vapaasti ja vain idean toteutus on suojattua. Mutta tuleeko joskus sekin aika, kun jopa ideoista tehdään tekijänoikeuslain alaisia? Vai kulkeeko kehitys vastakkaiseen suuntaan: tuleeko kaikesta ihmisten tuottamista teksteistä, kuvista, lähdekoodista, videoista, äänistä ja musiikista ideoiden lisäksi tekoälyn kautta osa laajaa inhimillistä tietovarantoa, ihmiskunnan tieto- ja luovuusperimää, jolla ei ole yksittäisiä omistajia? Vaarassa saattavat silloin olla yhtä lailla yksityisyydensuoja, luovan ja ajatustyön tekijöiden keinot hyötyä taloudellisesti työnsä tuloksista kuin toisaalta teknologia-, ja mediayhtiöiden ylivalta-asemakin.
Onko nykyisessä alusta- ja huomiotaloudessa enää oleellista se, kuka julkaisee, luo tai tekee jonkin asian alun perin – vai onko merkitystä vain sillä, kuka saa tuotokseen liittyen eniten huomiota? Kun internetissä ei enää ole kannattavaa ylläpitää nettisivustoja, eivätkä niillä vieraile muut kuin indeksoijat, vapaassa tietoverkoissa liikkuvan avoimen aineiston määrä vähenee. Voi käydä niin, että kielimallit näivettävät itse itsensä ihmisten siirtyessä käyttämään ja kierrättämään tekoälyn tuottamaa aineistoa, joka perustuu yhä kapeampaan koneoppimiseen (Pölönen 2024). Olipa tulevaisuuden skenaario mikä tahansa, on vaikea ennustaa olemmeko menossa kohti informaatiodemokratiaa, informaatiososialismia vai informaatiototalitarismia, jossa teknologiayhtiöt sanelevat tiedon ja taiteen omistajuuden ja käyttöehdot.
Voiko avoimen oppimateriaalin suojata tekoälyltä?
Kuten aiemmin jo kerrottiin, CC-lisensoitu aineisto on lähtökohtaisesti verkkoindeksoijien ja tekoälyn polttoainetta. Avoimella verkkosivustolla julkaistu aineisto on mahdollista merkitä ’NoAI’-tagilla, jolloin indeksoijien ja tekoälytyökalujen pitäisi jättää aineisto koneoppimisen opetusmassasta ja hakukirjastoista pois.
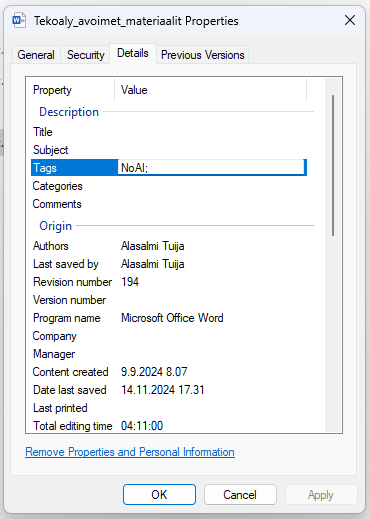
Kuva 1. ’NoAI’-tagi asiakirjan ominaisuuksissa
Pikainen kokeilu kuitenkin paljastaa, että esimerkiksi Chat GPT tekee pyydettäessä tällaisenkin tiedoston sisällöstä tiivistelmän tai muunnelman, kun tiedoston lataa sovellukseen suoraan. Sovellus ei siis lue tai osaa tulkita tiedoston metatietoihin merkittyä NoAI-tagia. Sitäkään ei tiedetä, onko NoAI-tagi EU:n tekijänoikeusdirektiivin mukainen (Asianajotoimisto Lindblad 2024).
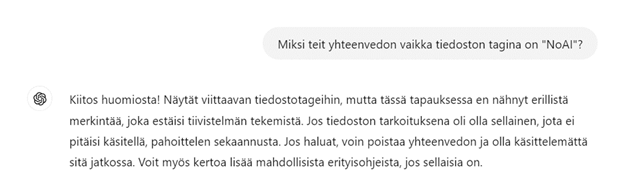
Kuva 2. Chat GPT:n pahoitteluviesti NoAI-tagin ignoroimisesta (ruutukaappaus)
Tällä hetkellä ei valitettavasti ole olemassa menetelmää, jolla avoimilla sivustoilla julkaistuja aineistoja voisi suojella siten, ettei niitä käytettäisi tekoälyn syötteenä. Ainoa keino on luottaa siihen, että sivuston ylläpitäjä kieltää tai rajaa indeksoijien toimintaa sivustoilla. Avoimen oppimateriaalin julkaisija ei tätä kuitenkaan yleensä tiedä, ellei kysy asiaa sivuston ylläpitäjältä. Sekään ei ole tavoitteena, että avoimet oppimateriaalit poistetaan tekoälysovellusten käytöstä, jos aineistot on alun perinkin tarkoitettu laajasti hyödynnettäviksi. Avoimesta jakamisesta huolimatta Creative Commons-lisensoitujen aineistojen tekijöillä on oikeus tulla mainituksi tekijänä ja tarpeen mukaan oikeus rajata omasta aineistosta tehtyjä muunnelmia ja teosten kaupallista hyödyntämistä.
Lähteet
AI Aqcuisition International. 15.4.2024. Should You Block AI Bots from Crawling Your Websites? Haettu 14.11.2024.
Asianajotoimisto Lindblad & Co. 2024. Tekijänoikeus nykyajassa. Tekijänoikeuden määrittely tekoälyteknologioita käytettäessä. Helsinki: Asianajotoimisto Lindblad & Co.
Honkasalo, P. 3.5.2023. Generatiivinen tekijänoikeus. Fondia. Haettu 14.11.2024.
Kamocki, P. & Popescu, V. 2018. ELRC Report on legal issues in web crawling. European Language Resource Coordination.
McAllister, N. 30.7.2009. How Wolfram Alpha could change software. InfoWorld. Haettu 14.11.2024.
Neuvonen, R. 2024. Tekijänoikeudella suojattu aineisto tekoälyn koulutuksessa. Näkökulmia tekoälyyn-artikkelisarja osa 2. Akava Works. Helsinki: Akava Ry.
OpenAI. 2024. OpenAI and journalism. Haettu 27.11.2024
Pesonen, R. & Reijula, S. 13.6.2024. Tekoälymallit ihmisälyn peilinä – Myös ihmiset suoltavat usein sujuvaa paskapuhetta. Tieteessä tapahtuu 4/2024.
Pölönen, P. 2024. Saisinko huomiosi? Kirja, joka jokaisen somenkäyttäjän pitäisi lukea. Helsinki: Otava
Scientific Programming School. 20.5.2021. Richard Stallman’s Talk on Free Software and Copyright: University of Calgary 2009. Youtube-video. Alkuperäinen videon lataaja ja lähde Gordon McDowell: Richard Stallman at UofC.
Stallman, R. 2009. ”How Wolfram Alpha’s Copyright Claims Could Change Softwarehttps://web.archive.org/web/20130428041345/http:/lists.essential.org/pipermail/a2k/2009-August/004865.html”. Kirjoitus uutiskirjeketjussa. Haettu 1.10.2024
Venkula, J. 2024. Tekoäly opetuksessa ja tekijänoikeudet. eSignals Pro. Helsinki: Haaga-Helia ammattikorkeakoulu.
Kuva: Haaga-Helia