Tekoäly
Julkaistu : 07.09.2022
Digitalisaatio sellaisena kuin se tällä hetkellä ymmärretään, tarjoaa käyttäjälle erilaisia tietolähteitä ja automatisaatiota ajasta ja paikasta riippumatta. Koko digitaalisen ympäristön käytettävyys on kokenut suuria muutoksia. Esimerkiksi puhelut hoituvat autoissa viihdejärjestelmän avulla älykkään hands-free-ominaisuuden kautta, komentoja voi antaa puheella kirjoittamisen sijaan tai ulkona liikuttaessa käyttäen langattomia kuulokemikrofoneja. Oma ja kohteen sijainti löytyy helposti mobiililaitteen GPS-ominaisuuksien ja karttasovelluksen avulla. Kaikki tämä vaatii tietolaitteistoilta paljon laskentatehoa, tietoliikennekapasiteettia ja yhä enemmän myös älyä. Tämä on pitkälti seurausta reunalaskennan kehityksestä (Yeung 2022). Parhaillaan on menossa älykkäiden toimintojen siirtymä keskitetyistä pilvipalveluista lähemmäs datan keräys- ja käyttökohdetta (Gartner 2022). Reunalaskennan kehittyminen on seurasta nopeasta datamäärän kasvusta, sekä tarpeesta parantaa tietoturvaa, skaalautuvuutta ja vaalia datan yksityisyyttä. Tässä artikkelissa valotamme mitä reunalaskenta on, miten se pääpiirteittäin toimii ja mikä on sen yhteys esineiden internetiin ja erityisesti tekoälyyn.
Reunalaskennan ajatus, edellytykset ja edut
Reunalaskenta (eng. edge computing), tarkoittaa tietojenkäsittelyä ja datan keräämistä lähellä käyttökohdetta keskitetyn laskennan, eli pilvipalvelun tai pilven, sijaan. Tyypillisiä reunalaskennan laitteita ovat esim. älypuhelimet, älykellot, erilaiset kehittyneet sensorit ja päätelaitteet. Pilvi sen sijaan käsittää esimerkiksi suuret kiinteät palvelinsalit ja datakeskukset. Nykyisin käytössä olevat tietotekniset ratkaisut kohtuullisen vaativaa reunalaskentaa varten ovat seurausta tekniikan kehityksestä, etenkin laskentatehon kasvusta, miniatyrisaatiosta ja laitteiden välisen kommunikaation tehokkuudesta.
Reunalaskennan tarkka määrittely on haastavaa. Erään näkemyksen mukaan kaikki laskenta, joka tapahtuu perinteisen keskitetyn palvelinsalin ulkopuolella, voi olla reunalaskentaa riippuen siitä kuka ja miten asiaa katsoo. Jos asiaa katsotaan datan näkökulmasta, voidaan yleistäen todeta, että reunalaskennan laitteet ovat sekä datan tuottajia että käyttäjiä. Pelkät sensorit ja muut yksinkertaiset reunalla sijaitsevat laitteet voivat kerätä dataa, mutta eivät käsitellä sitä, kun taas pilvipalvelut vain käyttävät muualta tulevaa dataa.
Kehitys kohti nykyistä reunalaskentaa alkoi käytännössä jo 1970-luvun puolivälistä lähtien, jolloin integroitujen piirien massatuotannon mahdollistamana voitiin tarjota käyttäjille lisää laskenta- ja muistikapasiteettia paitsi tehokkaampien keskuskoneiden, myös henkilökohtaisten työasemien avulla. Samoilla teknisillä lähtökohdilla voitiin kehittää myös monipuolisempaa ja tehokkaampaa tietokoneiden välistä langallista kommunikaatiota. Kun tähän yhdistettiin langattoman teknologian kehitys 1990-luvulla, saattoivat älykkäät, akuilla varustetut laitteet kommunikoida ilman kiinteitä yhteyksiä mobiilisti. Nämä kaikki tuottivat tarvittavat edellytykset itsenäistä, lähellä käyttöympäristöä tapahtuvaa, skaalautuvaa tietotekniikkaa varten.
Ajatus yhteen kytketyistä pienikokoisista ja tehokkaista tietojärjestelmistä on kytenyt automaatiotekniikan kanssa työskennelleiden mielessä yhtä kauan kuin antureita ja toimilaitteita on pystynyt ohjaamaan elektroniikan avulla – siis jo ennen integroitujen piirien aikakauden alkua. Tavoitteena olivat kyberfyysiset järjestelmät (eng. cyber-physical systems eli CPS), joiden toteutuksissa keskeisessä asemassa ovat autonomiset, kommunikoivat robotit.
Keskeisimmät vaatimukset, joihin reunalaskenta tarjoaa edellytykset, ovat seuraavat:
- Tosiaikaisuus. Jos kokonaisjärjestelmän vasteaikavaatimukset ovat tiukat, kuten esimerkiksi autonomisten ajoneuvojen tai potilaiden monitoroinnin tapauksessa, niin tällöin datan siirto tehokkaaseen pilvilaskentaympäristöön ja vastauksen palauttaminen takaisin vievät liikaa aikaa. Sama rajoitus koskee useimpia teollisuuden säätöprosesseja.
- Etäisyydet ja puutteelliset tietoliikenneyhteydet. Edellytettäessä järjestelmien keskeytymätöntä toimintaa tilanteissa, joissa verkkoyhteydet – niin virransaannin kuin tietoliikenteen osalta – ovat rajoitetut, on ainoa toimiva ratkaisu reunalaskenta sellaisella laitteistolla, mille voidaan taata tarvittava energia ja mikä kykenee tarvittavaan laskentaan sekä tiedon tallennukseen.
- Tietoturvallisuus. Tapauksissa, joissa kerättävä data on arkaluontoista, mutta tärkeää tekoälymallin opettamisen ja kehittämisen näkökulmasta, pitää pystyä tarjoamaan laskenta- ja tallennuspalvelut reunalla. Muutoin datan ja käyttäjien tietoturva voi vaarantua.
Erityisesti tietoturvan ja toimintavarmuuden kannalta reunalaskenta on houkuttelevaa. Reunalaskennan laitteet voidaan tarvittaessa irrottaa verkosta, jolloin ne eivät esimerkiksi ole alttiina yleisille verkon kautta tapahtuville palvelunestohyökkäyksille, joilla pilvipalvelut voidaan lamauttaa. On runsaasti sovelluksia, joissa keskitetty laskenta ei ole mahdollista suuren viiveen, tiedonsiirron ja yksityisyyden suojaamisen takia. Esimerkiksi liikenteen yhteydessä, kuten itsestään ajavat autot tai dronet, viive saa olla korkeintaan millisekunteja ja laskennan on toimittava riippumatta siitä, onko verkkoyhteyttä saatavilla joka hetki vai ei.
Laskennan eri tasoja lähtien palvelimista ja päätyen reunalaitteisiin on havainnollistettu kuvassa 1. Pilven ja reunan välissä olevaa kerrosta kuvataan toisinaan sanalla sumu ja puhutaan sumulaskennasta. Myös useita muita termejä, kuten mikrodatakeskus (eng. Micro datacenter) ja minipilvet (cloudlet), käytetään etenkin laitevalmistajien tahoilta. Sumulaskennassa pyritään yhdistämään pilvi ja reunalaskennan parhaita puolia, eli lokalisoida keskitettyjä laskentapalveluita lähemmäs reunaa esimerkiksi organisaation tasolle.
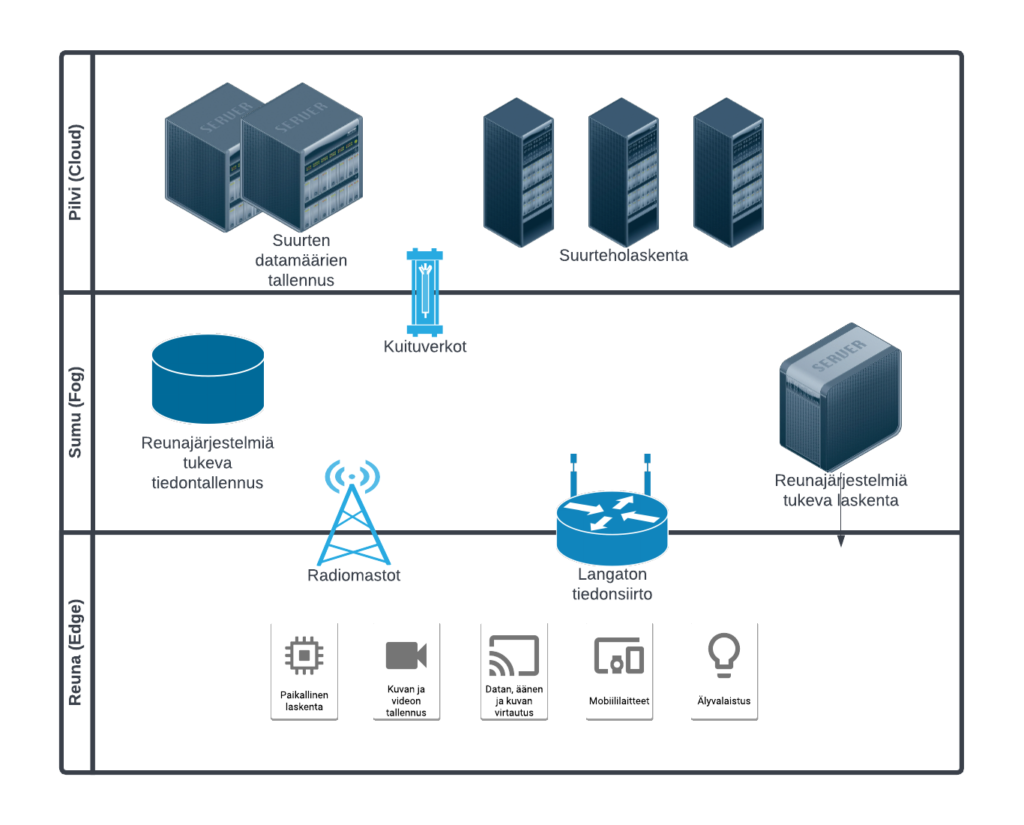
Esineiden internet osana reunaa
Esineiden internet (Internet of Things) – tutummin IoT – esiteltiin terminä ensimmäisen kerran vuonna 1997. Tuolloin johtavana ajatuksena oli varustaa kaikki mahdolliset esineet ja laitteet radiotunnisteilla (Radio Frequency IDentifier eli RFID), jotta niitä voitiin jäljittää ja tunnistaa samaan tapaan kuin oli tehty jo toisen maailmansodan aikana omien lentokoneiden ja laivojen erottamiseksi vihollisen aluksista.
Yhteistä edellä mainitulle CPS- ja IoT-määritelmille ovat käytettävien tietojärjestelmien tarjoama laskentakapasiteetti ja kehittynyt laitteiden välinen kommunikointi. Erilaisten sovellusten kehityksen myötä myös terminologia on sulautunut ja nykyään käytetään pääasiassa käsitettä IoT. 2000-luvun aikana tämän tosiasian ympärillä ovat eri toimijat konseptoineet malleja ja tiekarttoja omista lähtökohdistaan: tietoliikenneasiantuntijat korostavat kommunikaation skaalautumista ja puhuvat sumulaskennasta; tietokonejärjestelmien kanssa toimijat käyttävät puolestaan määritelmää reunalaskenta.
Mikä sitten on IoT:n ja reunalaskennan ero vai onko sitä? Yleisesti ottaen kaikki IoT laitteet, etenkään vanhemmat, eivät täytä reunalaskennan määritelmää lokaalista ja reaaliaikaisesta laskennasta. IoT laitteen keräämän datan analyysi on joko kevyttä ja/tai varsinainen analyysi tapahtuu muualla (esim. pilvessä). IoT laitteet suorittavat yleensä vain tiettyä rajattua tehtävää ja niiden ohjelmisto sekä prosessointikyky ovat hyvin rajalliset, jonka seurauksena niiden hinta, koko ja virrankulutus saadaan hyvin pieneksi. IoT laite on nimensä mukaisesti suunniteltu olemaan jatkuvassa yhteydessä verkkoon, kun taas reunalaskennan laite voi toimia myös itsenäisesti (Darling 2021).
Tekoälysovellukset reunalla eli reuna AI
Tekoälyn osuus tietokoneohjelmistojen, mallien ja algoritmien kehityksessä noudattaa varsin samaa kaavaa kuin reunalaskennan kehitys omalla sarallaan: Laitteisto- ja kommunikaatiotekniikan kehitys on ollut tärkein mahdollistaja tuotantomittaiselle soveltamiselle. Seuraava luonnollinen askel on ollut tekoälymallien ajaminen ja opettaminen reunalaskentaympäristössä. Nykyisin dataa tuotetaan niin paljon, että sen käsittelyn siirtyminen reunalle on huomattavasti tehokkaampaa, kuin kaiken datan käsittely keskitetysti. Kun tekoälyä hyödynnetään reunalaskennan laitteilla, käytetään monesti termiä reuna AI (eng. edge AI).
Tekoälyssä tarvittava laskennallinen malli toteutetaan koneoppimisen menetelmillä ja opetetaan aina datan avulla. Tämä osuus vaatii tavoiteltavasta mallista ja datan määrästä riippuen useimmiten niin runsaasti kapasiteettia, ettei sitä ole perusteltua tehdä reunalla. Koneoppimismallin opettaminen on laskennallisesti kallis tehtävä, joka toimii hyvin pilviympäristössä. Itse mallin käyttäminen päätelmien tekemiseen, eli inferenssiin, taas vaatii vain hyvin vähän laskentaresursseja. Näin ollen mallin voi laskea tehokkaassa pilviympäristössä ja siirtää sen reunalle käyttöön. Näin esimerkiksi mobiililaitteissa toimivat tekoälyt on toteutettu. Esimerkkejä ovat kielenkääntäjät, sekä kuvan ja äänen pohjalta tehtävät tunnistukset ajoneuvoista eläinlajeihin ja kasveihin.
Tekoälyn päivittäminen poikkeaa perinteisen tietokoneohjelman muokkaamisesta siten, että uuden datan avulla tekoälyä muutetaan ja korjataan käyttäen eri menetelmiä. Kuten ihmisten oppimisessa, myös tekoälymallien osalta puhutaan jatkuvuudesta ja jatkuvasta oppimisesta. Jatkuvuus ja virittäminen eri käyttöympäristöihin on tekoälymallin ylläpidolle haaste. Jos ajatellaan kokonaisprosessia, niin alkuperäinen malli opetetaan suurella, useimmiten avoimella datalla.
Kaiken tekoälylaskennan siirtäminen reunalle ei ole mahdollista, joten lopputulos siitä, missä laskenta lopulta tapahtuu, on kompromissi eri tekijöistä. Kuvassa 2 on listattu etuja, joita saavutetaan siirrettäessä tekoälymalli lähemmäs pilveä tai reunaa.

Erityisesti edge AI laitteiksi luokiteltavia laitteita voivat olla esimerkiksi älykaiuttimet, matkapuhelimet, älykellot, robotit, itseajavat autot, dronet ja videoanalytiikkaa hyödyntävät valvontakamerat. Reuna AI:n tärkeitä sovelluksia ovat muun muassa:
- Energiatehokkuuden kasvattaminen. Esimerkkinä ennakoiva energiankäyttö, joka mahdollistaa kysyntäjouston, kulutuksen seurannan ja ennakoinnin, uusiutuvan energian hyödyntämisen ja hajautetun energiantuotannon. Tämä vaatii keskinäistä viestintää, eikä dataa kannata kierrättää jatkuvasti keskitetyn pilvipalvelun kautta.
- Ennakoiva laitteiden vikaantuminen esim. tuotantolaitoksissa. Sensoridatan nopea analyysi vaatii laskentaa ja edistyneitä malleja.
- Terveydenhuollon laitteet ja instrumentit. Esimerkiksi kuvantamislaitteet ja potilaan tilan seurannassa käytetyt laitteet.
- Konenäön ratkaisut videokameroissa. Esimerkkinä automaattinen vartiointi ja kulunseuranta.
- Liikenteen ja kuljetuksen ratkaisut. Esimerkkeinä itseajavat autot ja ajamista avustavat järjestelmät, sekä itseohjautuvat dronet.
Reuna AI:n yleistymistä vauhdittavat erityisesti tekoälymallien nopea kehitys erityisesti syvien neuroverkkojen osalta, sekä uudet menetelmät mallien optimointiin reunalaitteille (esim. mallien harvennus ja kutistaminen), reunalaitteiden laskentatehon kasvu tekoälysovellusten vaatimalle tasolle, sekä IoT:n laaja käyttöönotto, jonka seurauksena reunalaitteiden määrä ja niiden keräämä datamassa ovat kasvaneet räjähdysmäisesti. Lisäksi 5G teknologia tarjoaa nopeamman ja turvallisemman tiedonsiirron, joka mahdollistaa suurempien datamassojen käytön.
Reuna AI:ta edistää huomattavasti myös erityiset mikropiirit (esim. NVIDIA Jetson ja Google Coral) ja ohjelmistot (esim. Tensorflow Lite), jotka mahdollistavat syvien neuroverkkojen käytön reunalaitteissa. Toisaalta monet uusista, edistyneimmistä tekoälymalleista, kuten DALL-E 2 (kuvien generointi) ja GPT-3 (tekstin generointi), vaativat suuren laskentaklusterin, eikä tämänkaltaisia malleja voida ainakaan lähitulevaisuudessa tuoda reunalle ilman jatkuvaa yhteyttä pilveen, jossa varsinainen syötteen prosessointi tapahtuu.
Reuna AI ja federoitu oppiminen
Nykyiset edistyneet koneoppimismallit ovat mahdollisia pitkälti siksi, että käytössä on valtavia datamassoja. Datan koostaminen, tallennus ja käsittely on kuitenkin työlästä ja kallista. Lisäksi mallien koulutus vaatii suuret määrät laskentatehoa. Työn hajauttaminen mallien luomisessa on näin ollen järkevää. Siirryttäessä aitoon käyttäjäympäristöön syntyy monesti myös tarve muokata tai räätälöidä koneoppimismallia kohteen datalla, jossa on huomioitu paikalliset erityispiirteet. Monesti käytössä on myös luottamuksellista ja sensitiivistä tietoa, jota ei haluta jakaa muille. Toisaalta kokonaisuuden kannalta olisi suotavaa, että uusimmat menetelmät ja mallit olisivat mahdollisimman laajassa käytössä (Qian 2019).
Eräs ratkaisu edellä mainittuihin ongelmiin on ns. federoitu oppiminen (eng. federated learning). Käsitettä kutsutaan myös yhteisöoppimiseksi (eng. collaborative learning), jossa kukin käyttäjä/taho virittää tekoälymallia itse omalla datallaan ja palauttaa sen alkuperäisen mallin kehittämistä varten ilman, että dataa tarvitsisi siirtää (Bonawitz 2019). Näin voidaan taata tietoturva, mikä on tärkeää lähes kaikissa käyttöympäristöissä (Xia 2021). Yhteys reunalaskentaan on siis ilmeinen.
Federoidun oppimisen periaate on yksinkertainen. Oppimisprosessissa toistetaan seuraavia askelia: (1) Oppimista ohjaava keskuskone valitsee reunalaskennan laitteet eli noodit ja lähettää niille mallin nykyiset parametrit, (2) noodit laskevat mallin omalla datalla ja ehdottavat parametrien muutoksen ja lopuksi ne (3) lähettävät ehdotuksensa takaisin keskuskoneelle, joka päivittää mallia ehdotusten mukaisesti. Käytännössä prosessi on monimutkaisempi ja jokainen vaihe sisältää pienempiä osaongelmia ja tehtäviä. Tehokkaiden opetusalgoritmien kehitys onkin tällä hetkellä kuuma tutkimusaihe. Prosessia on havainnollistettu kuvassa 3.
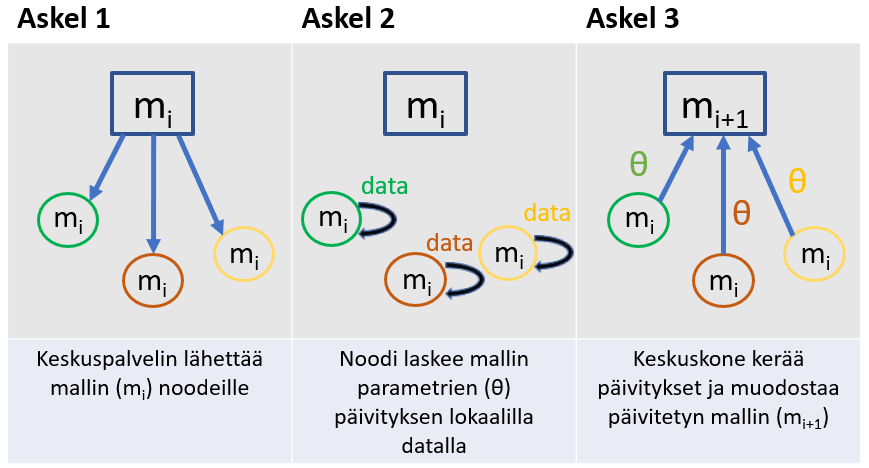
Federoidun oppimisen vahvuudet ovat erityisesti seuraavat:
- Nopeampi mallin laskenta, koska laskentatyö on hajautettu isolle joukolle
- Datan yksityisyys säilyy, koska omaa dataa ei tarvitse jakaa
- Datankeräyksen joukkoistaminen isolle joukolle datankerääjiä
- Mallien räätälöinti, koska yhteinen malli voidaan hienosäätää käyttäjän omalla datalla
Federoitua oppimista on hyödynnetty paljon erityisesti terveydenhuollon ja liikenteen alueilla. Terveyteen liittyvä data on erittäin yksityistä ja tiukan lainsäädännön alaista, joten sen jakaminen keskitetylle palvelimille on vain harvoin mahdollista. Koska ainoastaan mallin parametrit jaetaan toimijoiden kesken, federoidun oppimisen avulla mallit voidaan kouluttaa riippumatta siitä, millainen paikallinen lainsäädäntö datan jakamisen suhteen. Niin ikään autoilijoilta kerätty data, kuten GPS-sijainnit ja sensoridata ovat yksityistä tietoa, mutta kaiken datan hyödyntäminen on välttämätöntä, kun halutaan kehittää esim. itseajavia autoja jotka toimivat globaalisti ja yllättävissä tilanteissa. Molemmissa esimerkeissä mallien räätälöinti on myös tärkeää, jotta mallit toimivat optimaalisesti käyttäjän omassa ympäristössä.
Federoitu oppiminen ei ole kuitenkaan täysin ongelmatonta erityisesti seuraavasta kolmesta syystä (Yang 2019):
- Reunalaitteiden ja datan heterogeenisyys, jonka takia se mitä noodit tekevät ja miten ne vaikuttavat oppimisprosessiin, on vaikea ennustaa. Datan koko ja laatu eri noodeissa voi vaihdella suuresti.
- Tiedonsiirto ja kommunikaatio-ongelmat noodien ja keskuksen välillä. Noodeja voi tulla mukaan tai tippua pois eri vaiheissa opetusprosessia.
- Hyökkäykset, jossa yksittäiset noodit syöttävät tarkoituksella virheellistä tietoa keskuskoneelle. Tarkoituksena voi olla vääristää mallia tiettyyn – itselle edulliseen – suuntaan tai heikentää sitä.
Lisäksi ongelmana voi edelleen olla tekoälymallien selitettävyys ja läpinäkyvyys, joihin reuna AI tai federoitu oppiminen eivät tarjoa vastausta. Näihin on haettava ratkaisua muokkaamalla itse mallien matemaattista rakennetta ja toimintaperiaatetta, mikä ei suoraan vaikuta siihen miten malli opetetaan tai miten mallia käytetään (Wang 2022).
Yhteenveto
Olemme tässä artikkelissa avanneet reunalaskennan periaatetta ja sen yhteyttä tekoälyyn, esineiden internetiin ja edelleen federoituun oppimiseen. Erityisesti käsitteet pilvi, sumu, reuna ja esineiden internet sisältävät paljon päällekkäisyyttä ja rajat ovat monesti hyvin häilyvät. Parhaiten tästä termien viidakosta selviää, jos selvittää muutaman peruskysymyksen, kuten miten laite käsittelee dataa (keräys, analyysi vai molemmat), onko laite jatkuvassa yhteydessä tietoverkkoon, onko laite kiinteä vai liikuteltava ja miten edistynyttä laskentaa laite voi suorittaa. Erityisesti reuna AI ja federoitu oppiminen ovat keskeisiä tekijöitä, jotka mahdollistavat nykyisen nopean yhteiskunnan digitalisaation. Reunalaskenta ja federoitu oppiminen mahdollistavat edistyneiden ja räätälöityjen tekoälysovellusten laajan hyödyntämisen aikaan ja paikkaan sitoutumatta. Olemme todistaneet vasta alkua ja kehitys näillä aloilla on kiivasta sekä laitteiden, että uusien tekoälysovellusten alueella.
Viitteet
Bonawitz, K., Eichner, H., Grieskamp, W., Huba, D., Ingerman, A., Ivanov, V., Kiddon, C., Konečný, J., Mazzocchi, S., McMahan, H. B., Van Overveldt, T., Petrou, D., Ramage, D. & Roselander, J. 2019. Towards Federated Learning at Scale: System Design. Proceedings of Machine Learning and Systems 1 (MLSys).
Darling, Glen, 2021. IoT vs. Edge Computing: What’s the difference?
Qian, J., Gochhayat S. P. & Hansen, L. K. 2019. Distributed Active Learning Strategies on Edge Computing. 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/ 2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), pp. 221-226.
Wang, D., Wen, S., Jolfaei, A., Haghighi, M. S., Nepal, S. & Xiang, Y. 2021. On the Neural Backdoor of Federated Generative Models in Edge Computing. ACM Trans. Internet Technol. 22, 2, Article 43.
Xia, Q., Ye, W., Tao, Z., Wu, J. & Li, Q. 2021. A survey of federated learning for edge computing: Research problems and solutions, High-Confidence Computing, 1(1).
Yang, Q., Liu, Y., Chen, T. & Tong, Y. 2019. Federated machine learning: Concept and applications, ACM Trans. Intell. Syst. Technol., 10(2), 1–19.
Yeung, T. 2022. What Is Edge AI and How Does It Work?
Tämä kirjoitus on osa 3AMK:n tekoälytiimin toimintaa ja AI Forum hanketta. 3AMK tekoälytiimi on Haaga-Helian, Metropolian ja Laurean yhteinen tekoälyn asiantuntijaryhmä, joka keskittyy AI:n sovelluksiin erityisesti korkeakouluympäristössä. AI Forum on viiden suomalaisen korkeakoulun verkosto, jonka keskeinen tavoite on kartoittaa ja soveltaa tekoälyn uusimpia menetelmiä, suuntauksia ja käytäntöjä osana korkeakoulujen opetus- ja tutkimustoimintaa.